Introduction
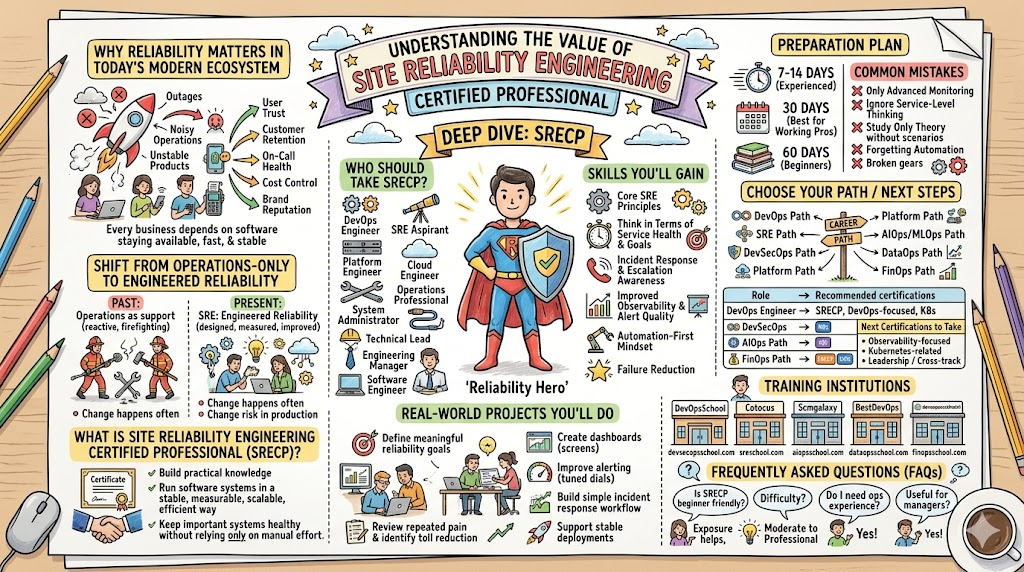
Every modern business depends on software staying available, fast, and stable. Users may never see the teams behind the product, but they notice the results immediately. They notice when an app loads slowly. They notice when payments fail. They notice when a dashboard stops updating, an API becomes unreliable, or a release causes unexpected downtime.
This is why reliability has become a core engineering responsibility.
In the past, many teams treated operations as a support function that came after development. That model does not work well anymore. Today, systems are spread across cloud platforms, containers, microservices, automation pipelines, APIs, and shared infrastructure. Changes happen often. Dependencies are deep. One weak point can affect the entire service chain. In this environment, reliability must be designed, measured, and improved continuously.
That is where Site Reliability Engineering, or SRE, becomes important.
SRE gives teams a practical way to think about uptime, performance, incident response, automation, observability, and operational quality. It helps organizations move from reactive firefighting to disciplined engineering. It also helps engineers and managers speak the same language when discussing risk, service quality, release speed, and customer impact.
The Site Reliability Engineering Certified Professional, known as SRECP, is designed for professionals who want to build that capability in a structured way. It is meant for people who do not want to remain limited to general operations knowledge. Instead, it helps them understand how modern reliability work is done in real environments.
This guide explains the certification in a practical, career-focused way. It covers what SRECP is, why it matters, why certifications are useful, why DevOpsSchool is a meaningful option, what skills you gain, how to prepare, how to choose your path, and what certifications to consider next.
What is Site Reliability Engineering Certified Professional (SRECP)?
Site Reliability Engineering Certified Professional is a certification built for people who want to develop practical knowledge in reliability engineering. It focuses on helping professionals understand how to run software systems in a stable, measurable, scalable, and efficient way.
In simple terms, SRECP is about learning how to keep important systems healthy in production without relying only on manual effort.
That sounds simple, but the real idea is much deeper. Reliability is not only about uptime. It is also about how services are monitored, how incidents are handled, how targets are defined, how alerts are tuned, how teams reduce repetitive work, and how engineering decisions affect business outcomes.
Many professionals already touch parts of this work in daily jobs. A DevOps engineer may manage deployments and monitoring. A cloud engineer may handle performance and infrastructure health. A platform engineer may support internal systems. A manager may own service quality and escalation flow. But often, these pieces stay disconnected.
SRECP helps connect them.
It gives professionals a reliability-focused framework so they can understand not only what they are doing, but why it matters and how the pieces fit together. Instead of thinking only in terms of servers, dashboards, or tickets, they begin thinking in terms of service behavior, reliability goals, recovery strategy, customer impact, and operational maturity.
That shift is what makes this certification valuable.
Why it Matters in Today’s Software, Cloud, and Automation Ecosystem
Software delivery has changed. Teams now release faster, scale wider, and depend on many more moving parts than before. Infrastructure is automated. Services are distributed. Monitoring produces massive amounts of data. Customer expectations are higher. Businesses want both speed and stability at the same time.
That creates a difficult challenge.
If teams move fast without reliability discipline, they create outages, noisy operations, and unstable products. If they focus only on stability and move too slowly, they lose agility and delay value delivery. Modern engineering teams need a balanced model that allows innovation without losing control.
SRE provides that balance.
It introduces a practical way to handle modern operational complexity. Instead of only reacting to failures, SRE asks important questions early:
What level of service should users actually expect?
How should we measure reliability in a useful way?
Which alerts deserve action and which ones only create noise?
How much operational work should remain manual?
What can be automated safely?
How do we recover from incidents better?
How do we reduce the chance of the same failure happening again?
These questions matter because software reliability now affects almost everything. It affects user trust, customer retention, engineering efficiency, on-call health, cost control, and brand reputation. In many companies, reliability is no longer just an engineering detail. It is a business issue.
For engineers, SRE provides a better way to think about production systems.
For managers, it provides a better way to guide teams, set expectations, and make decisions around service quality and operational readiness.
That is why SRE is no longer a niche skill. It is becoming a core capability across software, cloud, and platform teams.
Why Certifications are Important for Engineers and Managers
Experience is powerful, but experience alone is not always organized. Many professionals spend years in operations, cloud, DevOps, or support roles without ever getting a complete view of reliability engineering. They learn what their current team needs, but not always the larger model behind it.
A certification helps bring structure to that learning.
It creates a clear path. It helps professionals identify the right topics, understand the order in which they fit together, and build confidence around areas that may have felt scattered before.
For engineers, certifications are useful because they can turn partial experience into more complete capability. Someone may know monitoring tools but not understand service-level objectives. Another person may know infrastructure automation but not understand error-budget thinking. A certification helps fill those missing links.
It also helps career visibility. When a working engineer adds a role-relevant certification to real-world experience, it becomes easier for employers and hiring managers to understand the direction of that professional’s growth.
For managers, certifications are valuable in a different way.
Managers need a framework for team development. They need a clearer way to evaluate roles, identify training needs, and align operations with business goals. Reliability work often touches many teams at once. A certification gives managers a more structured language around service quality, incidents, observability, operational maturity, and engineering trade-offs.
A good certification does not replace real project work. It strengthens it. It gives shape to what people are already doing and helps them do it better.
Why Choose DevOpsSchool?
DevOpsSchool is also useful because it serves both individual professionals and teams. That makes it suitable for engineers growing in their own careers and for managers or organizations trying to build stronger reliability capability across projects.
Another strength is practical role alignment. SRECP is not only relevant for people already carrying the title of Site Reliability Engineer. It can also help DevOps engineers, platform engineers, cloud professionals, system administrators, and technical managers who are handling production systems and want to work with more clarity and discipline.
For learners who want a certification path that supports modern engineering roles instead of abstract academic learning, this can be a strong match.
Certification Deep-Dive: Site Reliability Engineering Certified Professional (SRECP)
What is this certification?
SRECP is a professional certification that teaches how reliability engineering works in modern software environments. It helps learners understand how to create and support dependable systems using a mix of engineering thinking, service measurement, automation, observability, and incident discipline.
It is not limited to one tool or one platform. Its value comes from helping professionals understand the larger reliability model behind production excellence.
Who should take this certification?
This certification is a strong fit for people who work close to production systems and want to improve the way those systems are managed.
It is especially suitable for DevOps engineers who want to deepen reliability skills.
It is useful for SRE aspirants who need a structured learning path.
It supports platform engineers who manage shared environments and service stability.
It benefits cloud engineers who own uptime, performance, and availability.
It can help operations professionals shift from manual support toward engineering-led operations.
It also makes sense for engineering managers who want to understand how modern teams should think about service quality, incident readiness, and operational maturity.
Certification Overview Table
| Certification Name | Track | Level | Who it’s for | Prerequisites | Skills covered | Recommended order | Link |
|---|---|---|---|---|---|---|---|
| Site Reliability Engineering Certified Professional (SRECP) | SRE | Professional | DevOps engineers, SRE aspirants, platform engineers, cloud engineers, operations professionals, engineering managers | Basic understanding of Linux, cloud, CI/CD, monitoring, and production environments is helpful | Reliability engineering, service objectives, incident management, observability, automation thinking, operational maturity, production stability | Strong first step in the SRE learning path | https://www.devopsschool.com/certification/sre-certified-professional-srecp.html |
Site Reliability Engineering Certified Professional (SRECP)
What it is
SRECP is a professional certification focused on building reliability thinking for modern software and cloud systems. It teaches how to approach service health, incident handling, monitoring, automation, and platform stability in a more disciplined way.
It is meant for professionals who want to move from task-based operations toward reliability-centered engineering.
Who should take it
- DevOps engineers
- SRE aspirants
- Platform engineers
- Cloud engineers
- Operations professionals
- System administrators
- Technical leads
- Engineering managers
- Software engineers who work closely with production systems
Skills you’ll gain
- Understanding of core Site Reliability Engineering principles
- Ability to think in terms of service health and service goals
- Better incident response and escalation awareness
- Improved understanding of observability and alert quality
- Stronger automation-first mindset for operations
- Clearer thinking around reliability versus release speed
- Better understanding of production readiness and failure reduction
- Improved collaboration language between engineering and management
- Stronger ability to reduce repetitive operational toil
- Better awareness of modern cloud and platform reliability practices
Real-world projects you should be able to do after it
- Define meaningful reliability goals for a service
- Create operational dashboards that support real decisions
- Improve alerting so teams act on the right signals
- Build a simple incident response workflow
- Review recurring support pain points and identify toil reduction opportunities
- Support stable deployment practices in production
- Improve observability for a cloud-based application
- Introduce service-level thinking into team discussions
- Help a platform team improve operational readiness
- Contribute to a reliability improvement plan for a production service
Preparation plan
7–14 days
This path works for experienced professionals who already operate in DevOps, cloud, or production roles. Use this time to revise core concepts, study the certification scope carefully, and connect each topic to your real work. Focus on service reliability thinking, observability basics, incident handling, and automation use cases.
30 days
This is the best option for most working professionals. Use the first part to understand concepts clearly. Use the second part to connect them with practical engineering examples. Use the last stretch for revision, scenario-based thinking, and lightweight hands-on practice. This approach helps move beyond memorization into actual understanding.
60 days
This is ideal for beginners or role changers. Start with Linux, cloud basics, monitoring, containers, CI/CD, and system operations. Then move into SRE concepts, service objectives, incident handling, observability, and reliability-focused workflows. Finish with review, note-making, and practical mini-project thinking.
Common mistakes
- Assuming SRE is only advanced monitoring
- Learning tools without learning reliability principles
- Ignoring service-level thinking
- Studying only theory without practical scenarios
- Treating incidents as isolated events instead of learning opportunities
- Forgetting the importance of automation in reducing toil
- Focusing only on outages and not on prevention
- Preparing without linking the content to real production situations
Best next certification after this
The right next certification depends on your career direction.
If you want to stay close to reliability, observability-focused learning is a natural next step.
If you want stronger infrastructure depth, Kubernetes-related certifications are a strong option.
If you want broader leadership or delivery ownership, a DevOps or management-oriented certification makes more sense.
Choose your path
DevOps
This path suits professionals who are strong in automation, CI/CD, release processes, and infrastructure delivery. SRECP adds deeper production reliability understanding and helps DevOps professionals move toward more mature service ownership.
DevSecOps
This path is suitable for people working in secure software delivery. Reliability and security often support each other. SRECP adds resilience, operational discipline, and stronger production response capability to a security-focused path.
SRE
This is the most direct path for people who want to specialize in service reliability, observability, incident management, and operational improvement. SRECP is a strong foundation for this route.
AIOps/MLOps
This path is useful for professionals working with AI-driven operations or machine learning systems. These environments still need reliability, visibility, and disciplined production practices. SRECP gives a strong foundation for that.
DataOps
Data systems also need stable pipelines, trustworthy platform operations, and predictable processing. SRECP helps DataOps professionals think more clearly about service behavior and operational quality.
FinOps
FinOps focuses on cost efficiency and cloud value. Better reliability often reduces waste, repeated recovery work, and emergency operational effort. That makes SRECP a smart complementary skill for professionals working in cloud cost governance.
Role → Recommended certifications
| Role | Recommended certifications |
|---|---|
| DevOps Engineer | SRECP, DevOps-focused certifications, Kubernetes-related certifications |
| SRE | SRECP first, then observability and advanced reliability certifications |
| Platform Engineer | SRECP plus Kubernetes, Terraform, and platform engineering learning |
| Cloud Engineer | SRECP plus cloud operations or cloud architecture certifications |
| Security Engineer | DevSecOps certifications first, then SRECP for resilience and operational depth |
| Data Engineer | DataOps learning plus SRECP for platform and service reliability |
| FinOps Practitioner | FinOps learning plus SRECP for efficiency and reliability alignment |
| Engineering Manager | SRECP plus leadership-focused DevOps, SRE, or platform strategy certifications |
Next certifications to take
Same track
An observability-focused certification is one of the best next moves after SRECP. Once you understand reliability from a service perspective, the next major advantage comes from deeper skill in metrics, logs, traces, dashboards, and monitoring design.
Cross-track
A Kubernetes-related certification is a strong cross-track option. Many modern reliability challenges happen in container-based systems, so stronger Kubernetes knowledge can make your SRE capability much more practical.
Leadership
A DevOps or engineering-management-oriented certification is a useful leadership step. This is especially helpful for professionals who want to move from hands-on technical work into platform leadership, engineering governance, or cross-team operational strategy.
List of top institutions which provide help in Training cum Certifications for Site Reliability Engineering Certified Professional (SRECP)
DevOpsSchool
DevOpsSchool is the direct provider of the SRECP certification and is the most relevant option for learners who want training aligned with the official program. It is well suited for working professionals who prefer practical, role-based learning. It is also a solid option for teams that want structured guidance in reliability engineering and service operations.
Cotocus
Cotocus is often considered by professionals looking for technical training and implementation-oriented support. It can be useful for learners who want stronger practical understanding in areas connected to cloud, automation, and modern engineering workflows. For those building reliability skills, that practical support can be helpful.
Scmgalaxy
Scmgalaxy is known in the broader technical learning space for DevOps, automation, and tool-focused education. It can be valuable for professionals who want to strengthen their core engineering foundations before moving deeper into specialized reliability subjects. This is particularly helpful for learners coming from general IT or support backgrounds.
BestDevOps
BestDevOps is often recognized in the wider DevOps and cloud training ecosystem. It can support professionals exploring role-based learning across automation, infrastructure, cloud operations, and engineering practices. For learners building a larger DevOps-to-SRE journey, it can be a useful supporting platform.
devsecopsschool.com
This platform is especially useful for learners who want to understand reliability alongside secure delivery practices. It can help professionals who are building careers in environments where uptime, compliance, resilience, and application security all need to work together.
sreschool.com
SRESchool is highly relevant for professionals who want focused growth in the reliability engineering space. It is a useful place for learners aiming to build stronger knowledge in service health, observability, alerting quality, incident handling, and reliability culture.
aiopsschool.com
AIOpsSchool can be useful for professionals who want to explore the future of operations through analytics, intelligence, and automation. It is especially relevant for those who want to combine foundational SRE practices with more advanced operational decision support.
dataopsschool.com
DataOpsSchool is valuable for professionals working on data platforms, pipelines, orchestration, and analytics operations. Reliability problems in data systems can be just as serious as application outages, so this can be a strong complementary learning option for data-focused professionals.
finopsschool.com
FinOpsSchool is useful for professionals interested in cloud spend efficiency, governance, and optimization. Since reliability and efficiency often influence each other, it can support learners who want to balance stable operations with better financial control in cloud environments.
FAQs
1. Is SRECP beginner friendly?
It is better suited to professionals with at least some exposure to Linux, cloud, monitoring, or operations. Beginners can still prepare for it, but they usually need more time and stronger foundational study first.
2. How difficult is the certification?
The difficulty is moderate to professional level. It is manageable for people already working near production systems, but it may feel challenging for those without practical technical exposure.
3. How long should I prepare?
A 30-day plan works well for many working professionals. Experienced engineers may prepare faster, while beginners may need around 60 days for stronger understanding.
4. Do I need prior operations experience?
It helps, but it is not the only valid background. DevOps, cloud, platform engineering, system administration, and even software engineering experience can all support SRE learning.
5. Is this certification useful for managers?
Yes. Managers benefit because it helps them understand reliability in a structured way and improves discussions around uptime, incidents, escalation, and operational maturity.
6. Is SRECP only useful for SRE job titles?
No. It is useful across many roles, especially DevOps, cloud operations, platform engineering, production engineering, and technical management.
7. Does it improve career growth?
Yes. It can strengthen your profile for roles that require better production understanding, service ownership, operational discipline, and reliability thinking.
8. What should I study before starting?
Linux basics, cloud fundamentals, monitoring concepts, CI/CD, containers, and production support workflows are all good starting points.
9. Should I take SRECP before Kubernetes certification?
That depends on your role. If your current work is more reliability-focused, SRECP is a strong first step. If your environment is deeply Kubernetes-heavy, either path can work well depending on your needs.
10. Will it help in real projects?
Yes. The value of SRECP becomes stronger when you apply it to dashboards, alerts, service health, incident response, and operational workflow improvement.
11. Is SRECP mainly theoretical?
No. It is most valuable when learned through practical thinking and real-world engineering scenarios, not only definitions.
12. Is this certification worth it for DevOps engineers?
Yes. Many DevOps engineers reach a stage where they need stronger production reliability depth. SRECP is a very practical next step for that transition.
FAQs on Site Reliability Engineering Certified Professional (SRECP)
1. What does SRECP stand for?
It stands for Site Reliability Engineering Certified Professional.
2. What is the main purpose of SRECP?
Its main purpose is to help professionals understand and apply reliability engineering practices in modern production environments.
3. Is SRECP useful for DevOps engineers?
Yes. It helps DevOps professionals grow beyond automation and deployment into stronger service reliability and operational maturity.
4. Can software engineers benefit from it?
Yes. Software engineers who work closely with backend systems, APIs, or production platforms can gain valuable reliability understanding from it.
5. Does it help engineering managers?
Yes. It helps managers better understand service quality, operational discipline, and incident readiness.
6. Is SRECP relevant for cloud-native systems?
Very much. Cloud-native systems are exactly the kind of environments where strong reliability practices matter most.
7. What makes SRECP different from general operations learning?
It focuses on engineering-led reliability rather than only task-based support work.
8. What is the biggest value of SRECP?
It helps professionals move from fragmented operational knowledge to a clearer, more complete reliability mindset.
Conclusion
Site Reliability Engineering Certified Professional is a strong certification for professionals who want to build real depth in modern reliability work. It is valuable because it does not stay limited to simple operations tasks or tool-specific learning. Instead, it teaches how service health, observability, incidents, automation, and production stability connect in real engineering environments. That makes it useful for DevOps engineers, SRE aspirants, cloud professionals, platform teams, and engineering managers alike. In a world where users expect systems to stay fast, available, and dependable, reliability has become one of the most important engineering capabilities. SRECP gives professionals a structured path to build that capability and apply it in a meaningful way.