Introduction
Modern software ecosystems demand more than just traditional code deployment; they require resilient systems that can withstand the pressures of global traffic. The Certified Site Reliability Professional program offers a definitive path for engineers who want to master the art of uptime and system health. SreSchool provides this specialized training to help professionals bridge the gap between software development and operational excellence. This guide empowers engineers to navigate the complexities of cloud-native infrastructure while making informed decisions about their technical growth.
What is the Certified Site Reliability Professional?
The Certified Site Reliability Professional represents a shift from reactive firefighting to proactive system engineering. It emphasizes the application of software engineering mindsets to solve infrastructure problems that traditional IT operations often struggle to manage. By focusing on production-grade environments, this certification ensures that engineers learn how to build self-healing systems rather than just maintaining servers.
It aligns perfectly with enterprise needs for scalability and high availability in distributed architectures. The curriculum prioritizes hands-on experience over abstract theory, forcing candidates to confront real-world failure scenarios and recovery protocols. Organizations today value this program because it creates a standard for reliability that directly impacts the bottom line and user trust.
Who Should Pursue Certified Site Reliability Professional?
Cloud engineers, DevOps practitioners, and backend developers find immense value in this certification as they move toward senior technical roles. System administrators seeking to modernize their skill sets will find the transition into reliability engineering both challenging and rewarding. Engineering managers also benefit by gaining the vocabulary and strategic insight needed to lead high-performing platform teams.
The program carries significant weight for professionals in India’s massive tech hubs and global engineers working in high-stakes industries like fintech and e-commerce. Beginners with a strong grasp of Linux and at least one programming language can use this as a launchpad for their careers. Experienced architects use it to validate their expertise in managing complex, multi-cloud environments effectively.
Why Certified Site Reliability Professional is Valuable
Companies face massive financial losses during every minute of downtime, which makes the Certified Site Reliability Professional an essential asset for any engineering team. It provides a long-term career advantage by teaching timeless principles of system design and observability that outlast specific software versions. Professionals gain the ability to quantify reliability, allowing them to communicate technical risks to business stakeholders clearly.
The certification drives significant ROI by reducing the time engineers spend on manual “toil” and increasing the time they spend on innovation. It positions you as a high-value specialist capable of managing the lifeblood of digital enterprises. As organizations continue their migration to microservices and Kubernetes, the skills validated by this program become the industry’s most sought-after competencies.
Certified Site Reliability Professional Certification Overview
The certification uses a tiered approach to ensure that learners build a solid foundation before tackling advanced architectural challenges. Every level requires candidates to pass rigorous assessments that simulate the pressures of a live production environment.
The structure focuses on practical ownership, meaning engineers learn to take responsibility for the entire service lifecycle. By hosting the program on SreSchool, the creators ensure that the content remains fresh and reflects the latest shifts in the cloud-native landscape. This overview serves as a roadmap for anyone ready to commit to the highest standards of operational engineering.
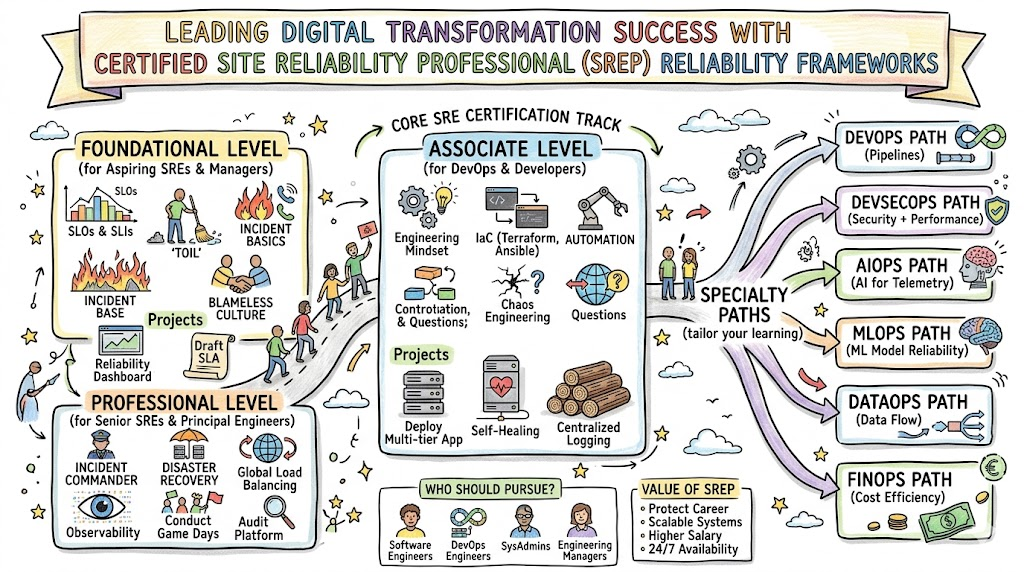
Certified Site Reliability Professional Certification Tracks & Levels
The program splits into three distinct difficulty tiers: Foundational, Associate, and Professional. The Foundational level builds the core vocabulary of reliability, while the Associate level focuses on the day-to-day implementation of monitoring and incident management. The Professional level challenges senior engineers to design resilient systems that can survive catastrophic regional failures.
Beyond these tiers, specialization tracks allow engineers to focus on specific domains like security, finance, or artificial intelligence. These tracks align with career progression, helping junior engineers become specialists and specialists become technical leaders. Each level acts as a stepping stone, ensuring a logical and comprehensive mastery of site reliability engineering.
Complete Certified Site Reliability Professional Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundational | Freshers/Junior Devs | Basic Linux knowledge | SLIs, SLOs, Toil | 1 |
| Implementation | Associate | DevOps/SREs | 1 Year Experience | Observability, Incidents | 2 |
| Architecture | Professional | Senior SREs/Leads | 3+ Years Experience | Chaos Eng, Scaling | 3 |
| Security Focus | Specialty | Security Engineers | Security Basics | DevSecOps, Compliance | Optional |
| Financial Focus | Specialty | Cloud Architects | Cloud Fundamentals | FinOps, Cost Control | Optional |
| Data Focus | Specialty | Data Engineers | SQL/Big Data Basics | Data Reliability, Pipelines | Optional |
Detailed Guide for Each Certified Site Reliability Professional Certification
Foundational Level
Certified Site Reliability Professional – Foundational
What it is
This introductory certification establishes the core mindset required to think like a reliability engineer. It validates that a candidate understands the fundamental concepts of error budgets and the reduction of manual operations.
Who should take it
Aspiring engineers and computer science graduates should start here to build a professional vocabulary. It also serves non-technical managers who need to understand how their teams measure system success.
Skills you’ll gain
- Defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Calculating Error Budgets to balance feature velocity and stability.
- Identifying and categorizing “toil” within daily operations.
- Understanding the basic architecture of a monitoring system.
Real-world projects you should be able to do
- Draft a basic SLO document for a simple web service.
- Create a manual inventory of recurring tasks and suggest automation steps.
- Set up basic uptime monitoring for a personal website or application.
Preparation plan
- 7–14 days: Read the official SRE literature provided by SreSchool and memorize key definitions.
- 30 days: Practice calculating error budgets using hypothetical outage data.
- 60 days: Implement a basic monitoring stack on a local virtual machine to visualize uptime.
Common mistakes
- Candidates often confuse the legal requirements of an SLA with the technical goals of an SLO.
- Many try to automate complex processes before they fully understand the manual steps.
Best next certification after this
- Same-track option: Associate Level Certification.
- Cross-track option: DevOps Foundations.
- Leadership option: Project Management Basics.
Associate Level
Certified Site Reliability Professional – Associate
What it is
The Associate level marks the transition into active system management and incident response. It proves that an engineer can handle production alerts and maintain observability across a distributed system.
Who should take it
Mid-level DevOps engineers and system administrators will find this level most applicable to their daily work. It targets those who spend significant time on-call or managing cloud infrastructure.
Skills you’ll gain
- Configuring advanced observability using logs, metrics, and distributed traces.
- Leading incident response efforts and coordinating technical teams during outages.
- Developing automated self-healing scripts to resolve common failures.
- Facilitating blameless post-mortems to drive organizational learning.
Real-world projects you should be able to do
- Build a centralized logging system for a multi-service application.
- Design an on-call rotation and alerting policy that minimizes fatigue.
- Write a post-mortem report that identifies systemic root causes of a failure.
Preparation plan
- 7–14 days: Master the use of monitoring tools like Prometheus and logging stacks like ELK.
- 30 days: Simulate a multi-component outage and practice the triage process.
- 60 days: Audit an existing system’s observability and fill the gaps in its metrics.
Common mistakes
- Focusing solely on fixing the immediate problem rather than the systemic cause.
- Creating too many low-priority alerts that mask critical system failures.
Best next certification after this
- Same-track option: Professional Level Certification.
- Cross-track option: Certified DevSecOps Specialist.
- Leadership option: SRE Team Lead Training.
Professional/Specialty Level
Certified Site Reliability Professional – Professional
What it is
This elite certification validates the highest level of expertise in architecting for failure at scale. It focuses on the most complex aspects of reliability, including chaos engineering and global traffic management.
Who should take it
Senior SREs, Principal Engineers, and Cloud Architects with years of production experience should pursue this. It is for those responsible for the reliability of mission-critical global services.
Skills you’ll gain
- Designing and executing chaos engineering experiments to harden systems.
- Architecting multi-region failover strategies and disaster recovery plans.
- Managing complex capacity planning and performance tuning at scale.
- Building custom automation tools to manage thousands of nodes.
Real-world projects you should be able to do
- Conduct a “Game Day” exercise where you intentionally break a production-like system.
- Design a database replication strategy that guarantees zero data loss during failure.
- Automate the scaling of a global application based on real-time latency metrics.
Preparation plan
- 7–14 days: Deep dive into advanced distributed system design patterns.
- 30 days: Build and test a full disaster recovery environment from scratch.
- 60 days: Lead a major architectural change that improves system availability by “one nine.”
Common mistakes
- Underestimating the cultural difficulty of implementing chaos engineering in a large company.
- Building over-engineered solutions that are too difficult for the team to maintain.
Best next certification after this
- Same-track option: Fellow/Distinguished Engineer status.
- Cross-track option: Certified FinOps Architect.
- Leadership option: Director of Engineering / CTO Track.
Choose Your Learning Path
DevOps Path
Engineers on the DevOps path focus on the speed of delivery without sacrificing the quality of the software. They master CI/CD pipelines and treat infrastructure as code to ensure that every deployment is repeatable and reliable. This path bridges the gap between the development sprint and the stable production environment.
DevSecOps Path
The DevSecOps path integrates security checks directly into the automated reliability lifecycle. Professionals here ensure that every code change undergoes rigorous security scanning before it reaches the production environment. They treat security as a fundamental component of system uptime and data integrity.
SRE Path
The SRE path represents the purest application of engineering principles to operations. These professionals prioritize observability and the constant reduction of manual toil through sophisticated automation. This path is ideal for those who want to specialize in the internal mechanics of high-scale systems.
AIOps Path
AIOps specialists use artificial intelligence to manage the overwhelming amount of data generated by modern systems. They build models that can predict outages before they happen and automate complex troubleshooting steps. This path suits engineers interested in the intersection of data science and operations.
MLOps Path
MLOps professionals apply reliability principles to the unique lifecycle of machine learning models. They ensure that training data flows correctly and that deployed models remain performant and accurate in production. This path is essential for organizations that rely on AI for their core business logic.
DataOps Path
DataOps focuses on the reliability and velocity of data pipelines across an organization. These engineers ensure that data flows seamlessly from sources to analytics platforms with high integrity and low latency. This path adapts SRE practices to manage the complexities of big data and database systems.
FinOps Path
FinOps experts manage the financial health of cloud-native systems by optimizing resource usage. They correlate cloud costs with engineering metrics to ensure the business gets the most value from its infrastructure spend. This path is critical for managing large-scale cloud budgets effectively.
Role → Recommended Certified Site Reliability Professional Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Foundational, Associate, DevSecOps Track |
| SRE | Foundational, Associate, Professional |
| Platform Engineer | Associate, Professional, FinOps Track |
| Cloud Engineer | Foundational, Associate, FinOps Track |
| Security Engineer | Foundational, DevSecOps Track |
| Data Engineer | Foundational, DataOps Track |
| FinOps Practitioner | Foundational, FinOps Track |
| Engineering Manager | Foundational, SRE Leadership Path |
Next Certifications to Take After Certified Site Reliability Professional
Same Track Progression
Completing the professional level opens the door to becoming a Principal SRE or a Reliability Architect. You should focus on gaining deep expertise in specific cloud platforms like AWS or Azure to complement your general reliability skills. Industry-leading specialized courses in high-performance computing or advanced networking also provide a natural progression for those staying on the technical track.
Cross-Track Expansion
Broadening your expertise into security or cost management creates a more versatile professional profile. Many SREs find that earning a DevSecOps certification allows them to address a wider range of production risks. Similarly, mastering FinOps allows you to have more impact on the business’s bottom line, making you an ideal candidate for senior leadership roles.
Leadership & Management Track
If you enjoy mentoring and strategy, transition toward the Engineering Management track. Focus on certifications that teach team dynamics, strategic planning, and budget management. Moving from managing systems to managing the people who build them requires a shift in focus from technical reliability to organizational health.
Training & Certification Support Providers for Certified Site Reliability Professional
- DevOpsSchool
DevOpsSchool stands out as a premier destination for engineers seeking to master the intricacies of site reliability and automated operations. They provide a robust curriculum that balances intense technical labs with deep theoretical dives into the SRE mindset. Their trainers bring decades of collective industry experience, ensuring that every student learns how to navigate real-world production crises with confidence and technical precision. - Cotocus
Cotocus specializes in providing high-impact technical consulting and training for modern enterprises navigating cloud-native transformations. Their approach to the certification program emphasizes the architectural patterns required to scale infrastructure globally while maintaining strict reliability standards. They offer customized workshops that allow engineering teams to practice SRE principles on their own specific technology stacks, making the learning process highly relevant and immediately applicable. - Scmgalaxy
Scmgalaxy has built a massive global community around software configuration management and the broader DevOps ecosystem. They offer a wealth of free resources, tutorials, and specialized training sessions that help professionals stay current with evolving reliability trends. Their support for the certification track includes access to a network of experts who provide mentorship and guidance throughout the challenging journey from foundational to professional levels. - BestDevOps
BestDevOps focuses on delivering highly curated training experiences that prioritize the most practical and in-demand skills in the current tech market. Their programs help engineers cut through the noise and focus on the tools and methodologies that drive actual system stability. They provide comprehensive study guides and simulated exam environments that prepare candidates for the rigors of the certification assessment while building lasting technical competence. - devsecopsschool.com
devsecopsschool.com provides a unique focus on the intersection of security and site reliability engineering. They teach candidates how to build “secure by design” systems that can withstand both technical failures and malicious attacks. Their curriculum is an essential resource for SREs who want to specialize in protecting sensitive data while maintaining the high availability standards required by modern digital enterprises. - sreschool.com
sreschool.com acts as the primary authority and hosting platform for the entire certification ecosystem. By learning directly from the source, candidates ensure that their training perfectly matches the latest exam objectives and industry benchmarks. They provide a holistic learning environment that includes interactive labs, community forums, and direct access to the creators of the reliability frameworks taught in the program. - aiopsschool.com
aiopsschool.com leads the way in teaching engineers how to leverage machine learning for smarter IT operations. They offer specialized modules that show SREs how to use data-driven insights to automate the detection and resolution of complex system anomalies. This provider is ideal for professionals who want to stay at the cutting edge of automation and the future of self-healing infrastructure. - dataopsschool.com
dataopsschool.com addresses the specific reliability challenges found in the world of big data and real-time analytics. They adapt core SRE principles to manage the unique failure modes of data pipelines and large-scale database clusters. Their training ensures that data engineers can provide the same level of uptime and performance for data services that SREs provide for application services. - finopsschool.com
finopsschool.com focuses on the critical intersection of cloud engineering and financial management. They teach professionals how to correlate infrastructure performance with business costs, ensuring that reliability does not lead to runaway expenses. Their courses provide the analytical tools and engineering strategies needed to build cost-efficient cloud environments that scale profitably for the organization.
Frequently Asked Questions
1. Does the exam require coding skills?
Yes, you must demonstrate the ability to write scripts in languages like Python or Go to automate common operational tasks.
2. How long is the certification valid?
The certification remains active for two years, after which you must renew it or advance to the next level.
3. Is there an age or experience limit for the foundational level?
There is no age limit, and the foundational level is open to anyone with a basic understanding of computer systems.
4. Can I jump straight to the professional level?
No, you must successfully complete the associate level to ensure you have the required hands-on experience for the professional exam.
5. How much time should I dedicate to studying every day?
We recommend at least two hours of focused study and lab work per day to stay on track for your 30 or 60-day goal.
6. Does the program cover Kubernetes?
Yes, Kubernetes is a core part of the Associate and Professional levels, as it is the industry standard for container orchestration.
7. Are the exams multiple-choice or performance-based?
The exams use a combination of theoretical questions and performance-based tasks that require you to solve problems in a live environment.
8. What happens if I fail the exam on my first try?
SreSchool allows for retakes after a mandatory waiting period, during which you should focus on the areas where you struggled.
9. Is this certification better than a general DevOps cert?
This certification is more specialized and focuses specifically on reliability, which is often a more highly-paid and niche skill set.
10. Do I get a physical certificate?
You receive a verifiable digital badge and a high-resolution digital certificate that you can easily share on LinkedIn and other platforms.
11. Is the training available in languages other than English?
Currently, the primary language for the training and the exam is English, though community support exists in several other languages.
12. Does the certification include cloud-specific training?
The principles are cloud-agnostic, but the labs often use AWS or Google Cloud to demonstrate how to implement those principles.
FAQs on Certified Site Reliability Professional
1. How does this certification address the concept of “Blameless Culture”?
The program teaches that system failures are usually the result of architectural weaknesses rather than individual human errors. In the exam and training, you learn how to conduct post-mortems that focus on fixing the system instead of punishing the person. This cultural shift is vital for building a team that isn’t afraid to innovate or report problems early. By mastering this, you become a leader who fosters psychological safety while simultaneously driving the highest standards of technical excellence within your organization.
2. What role does math play in the CSRP curriculum?
You will need a basic grasp of statistics to calculate availability percentages and determine appropriate threshold levels for alerts. The course shows you how to use data to justify why a system needs a 99.9% uptime goal versus a 99.99% goal. This mathematical foundation prevents “alert fatigue” by ensuring that only statistically significant anomalies trigger an engineer’s intervention. It allows you to move from guessing about system health to making decisions based on rigorous, quantifiable evidence that stakeholders can understand.
3. Does the Professional level cover global traffic management?
Yes, the professional tier explores how to manage user requests across multiple geographical regions using Global Server Load Balancing (GSLB). You learn how to architect systems that can automatically reroute traffic if an entire data center or cloud region goes offline. This involves understanding latency, data synchronization challenges, and DNS-based failover strategies. Mastering these concepts ensures that you can support global enterprises that require 24/7 availability for millions of users regardless of their physical location or local infrastructure issues.
4. How do I practice for the hands-on lab portion of the exam?
SreSchool provides integrated lab environments where you can experiment with real tools like Terraform, Prometheus, and Kubernetes. We recommend building your own “mini-production” environment locally using Docker or a small cloud account to practice different failure scenarios. The more you “break” and “fix” your own systems, the more prepared you will be for the performance-based tasks in the certification. Practical familiarity with the command line and common troubleshooting tools is the single biggest factor in passing the associate and professional exams.
5. Why is “Toil” a major focus of the certification?
Toil refers to manual, repetitive, and tactical work that provides no long-term value and scales linearly with service growth. The certification teaches you how to identify this burden and eliminate it through software engineering. By reducing toil, you free up the team’s time to work on “engineering” tasks that improve the system’s architecture and future reliability. Organizations value this skill because it allows them to scale their services without needing to hire a proportional number of operations staff, significantly improving efficiency.
6. How does the specialty track in FinOps complement the SRE core?
While the core SRE tracks focus on uptime, the FinOps specialty ensures that uptime remains affordable. In the cloud, it is easy to achieve reliability by over-provisioning resources, but this leads to massive waste. FinOps teaches you how to use “rightsizing” and “spot instances” to maintain performance while slashing the cloud bill. This dual expertise makes you an invaluable bridge between the engineering department and the finance department, as you can speak both the language of “latency” and the language of “margins.”
7. Is Chaos Engineering actually safe for production environments?
The course teaches that Chaos Engineering is not about “breaking things randomly” but about “planned experiments” to verify system resilience. You learn how to start small in staging environments and gradually move to production once you have high confidence in your system’s steady state. The goal is to uncover hidden weaknesses before they cause a real outage. This proactive approach to testing failure modes is what separates a senior SRE from a traditional administrator who only reacts to problems after they occur.
8. What is the difference between white-box and black-box monitoring in the exam?
White-box monitoring uses internal system data, like logs and internal metrics, to understand exactly what is happening inside the application. Black-box monitoring tests the system from the outside, like a user would, to see if the service is actually reachable and functional. The CSRP curriculum teaches you how to combine both approaches to get a 360-degree view of system health. You learn which signals are best for immediate alerting and which are best for long-term trend analysis and capacity planning.
Final Thoughts: Is Certified Site Reliability Professional Worth It?
Investing in the Certified Site Reliability Professional program represents a commitment to becoming a top-tier engineer in a world that runs on code. The skills you gain here go beyond mere tool knowledge; they transform how you perceive and manage the invisible complexity of modern digital infrastructure. This certification proves that you can be trusted with the most critical systems of a global enterprise. Success in this field requires a balance of technical rigor and a mindset focused on continuous improvement. As you move through this roadmap, focus on the principles that connect different technologies rather than just the technologies themselves. If you are ready to stop reacting to failures and start engineering for success, this certification provides the most clear and direct path to the peak of your career.